正規化(基本)
非正規形
伝票データそのまま
| 伝票番号 | 注文日 | 明細番号1 | 商品コード1 | 商品名1 | 数量1 | 明細番号2 | 商品コード2 | 商品名2 | 数量2 |
|---|---|---|---|---|---|---|---|---|---|
| a01 | 2018/01/08 | b01 | X1 | 商品1 | 10 | b02 | X2 | 商品2 | 10 |
| a02 | 2018/01/09 | b01 | X1 | 商品1 | 20 |
第1正規形
伝票テーブル
| 伝票番号 | 注文日 | 明細番号 | 商品コード | 商品名 | 数量 |
|---|---|---|---|---|---|
| a01 | 2018/01/08 | b01 | X1 | 商品1 | 10 |
| a01 | 2018/01/08 | b02 | X2 | 商品2 | 10 |
| a02 | 2018/01/09 | b01 | X1 | 商品1 | 20 |
テーブルの中の繰り返し項目をなくす。
第2正規形
伝票ヘッダテーブル
| 伝票番号 | 注文日 |
|---|---|
| a01 | 2018/01/08 |
| a02 | 2018/01/09 |
伝票明細テーブル
| 伝票番号 | 明細番号 | 商品コード | 商品名 | 数量 |
|---|---|---|---|---|
| a01 | b01 | X1 | 商品1 | 10 |
| a01 | b02 | X2 | 商品2 | 10 |
| a02 | b01 | X1 | 商品1 | 20 |
主キーが複数項目で構成されている場合、主キーを分けられるようであれば分ける。
(ヘッダ、明細みたいな関係があれば分ける)
第3正規形
伝票ヘッダテーブル
| 伝票番号 | 注文日 |
|---|---|
| a01 | 2018/01/08 |
| a02 | 2018/01/09 |
伝票明細テーブル
| 伝票番号 | 明細番号 | 商品コード | 数量 |
|---|---|---|---|
| a01 | b01 | X1 | 10 |
| a01 | b02 | X2 | 10 |
| a02 | b01 | X1 | 20 |
商品マスタテーブル
| 商品コード | 商品名 |
|---|---|
| X1 | 商品1 |
| X2 | 商品2 |
※緑色は外部キー
外部キーとなりえる項目があれば分ける。
(マスタにできそうな項目は分ける)
トランザクション分離レベル
| ダーティリード | ノンリピータブルリード | ファントムリード | |
|---|---|---|---|
| READ UNCOMMITTED ( 確定していないデータまで読み取る ) | 発生 | 発生 | 発生 |
| READ COMMITTED ( 確定した最新データを常に読み取る ) | - | 発生 | 発生 |
| REPEATABLE READ ( 読み取り対象のデータを常に読み取る ) | - | - | 発生 |
| SERIALIZABLE ( 直列化可能 ) | - | - | - |
| 用語 | 説明 |
|---|---|
| ダーティーリード | 他のトランザクションのコミット前のデータを読み込む。 |
| ノンリピータブルリード | 同じデータを2回読み込んだ時に他のトランザクション結果により読み取り結果が異なる。 |
| ファントムリード | 別トランザクションがデータ追加したことにより、読み取り結果が異なる。 |
| ロストアップデート | あるトランザクションが更新した内容を無視して別トランザクションが上書きで更新してしまい、元のトランザクションが更新した内容が消えること。 |
集合
| 名称 | SQL | 記号 | イメージ |
|---|---|---|---|
| 和 | SELECT * FROM tableA UNION SELECT * FROM tableB |
\(A \cup B\) | 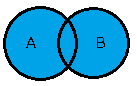 |
| 積 | SELECT * FROM tableA INTERSECT SELECT * FROM tableB |
\(A \cap B\) | 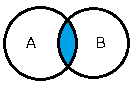 |
| 差 | SELECT * FROM tableA EXCEPT SELECT * FROM tableB または SELECT * FROM tableA MINUS SELECT * FROM tableB |
\(A - B\) | 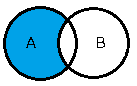 |
| 直積 | SELECT * FROM tableA CROSS
JOIN tableB または SELECT * FROM tableA , tableB |
\(A \times B\) | |
| 商(除算) | \(A \div B\) | 関係演算R÷Sの場合、関係Rの中で関係Sの全ての項目を含む行 |
表の結合アルゴリズム
| 名称 | 説明 |
|---|---|
| 入れ子ループ法 | 1行毎に全組み合わせを比較。 タプル数nの表二つに対する結合操作の計算量は\(n^2\) |
| ソートマージ法 | ソートしてから結合。 |
| ハッシュ法 | ハッシュ関数を使用。等結合しか使用できない。 |
テーブルの用語
| 用語 | 説明 |
|---|---|
| 属性 | 列。 |
| 次数 | 属性の数。SELECT A,B,C FROM TBL であれば3。 |
| タプル | 行。組。 |
| ドメイン | 定義域。データ型。属性が取り得る値の集合。 |
| 射影 | 指定した列(属性)だけを抽出する演算。 |
| 選択 | 指定した行(タプル)だけを抽出する演算。 |
ロック
複数のトランザクションを同時に実行したときに、それぞれのトランザクションを個別に実行したときと同じ結果になることを直列化可能性を持っているという。直列化可能性を持たせるため排他制御を行うが、その制御を行うためにロックを使用する。
ロックには共有ロックと占有ロックがある。
共有ロック同士であれば別のトランザクションから同じデータに対しロックをかけられるが、共有ロック⇔占有ロック、占有ロック⇔占有ロックはロックをかけることができない。
| 共有ロック | 占有ロック | |
|---|---|---|
| 共有ロック | O | X |
| 占有ロック | X | X |
Oracleの場合、SELECT実行時に FOR UPDATE を付けると占有ロックになる。共有ロックはSELECT時に指定できない。
PostgreSQLの場合、SELECT実行時に FOR SHARE を付けると共有ロックになる。
| 用語 | 説明 |
|---|---|
| 2相ロック | 分散データベースの2相コミットとは別物。トランザクションを実行する前に対象データをすべてロックし(第1フェーズ:成長相)処理後に開放する(第2フェーズ:縮退相)というもの。
サイドロックをかけ直すことはできない。デッドロックも防げない。 トランザクションの競合直列可能性が保証される。 |
| 待ちグラフ | デッドロック検出で使用。この方法以外ではロック待ちトランザクションの経過時間を計測してデッドロックを検出する方法がある。 |
| 時刻印アルゴリズム | 競合が発生しても先のトランザクションから順番に実行することでデッドロックを回避。 |
| 楽観アルゴリズム | 処理終了時に他のトランザクションで更新していないか確認し、更新されていたら更新処理を破棄し再度、処理を行う。 |
| チェックポイント | メモリと他の記録装置のデータ同期。トランザクション処理中も実行される。 |
| WAL | Write Ahead Log。ログ先書き。データベース更新前に更新前イメージログ、更新後イメージログが出力される。 |
分散データベース
| 用語 | 説明 |
|---|---|
| 2層コミットメント | コミット前に各データベースにコミット可能か確認してOKならコミットする。 |
| 透過性 | データの物理格納場所やプログラムの実行場所を意識させない |
| 移動に対する透過性 | 格納場所を変えても気付かれない |
| 分散に対する透過性 | 分散配置されても気付かれない |
| 重複に対する透過性 | 複数サイトに重複して格納しても気付かれない |
| 分割に対する透過性 | 複数サイトに分割して格納しても気付かれない |
データベースサーバのクラスタリング技術
| 用語 | 説明 |
|---|---|
| シェアードエブリシング | アクティブ-アクティブ構成によって負荷分散を行うことによって,サーバリソースの有効活用が可能となり,さらにデータが共有されているので,1台のサーバの障害発生時でも処理を継続することができる。 |
| シェアードナッシング | HA構成を用いたクラスタリングを行い,障害発生時には待機系のサーバに担当していたデータ範囲を引き継ぐことができる。 サーバごとに管理する対象データが決まっているので,1台のサーバに障害が発生すると対象データを処理できなくなり,システム全体の可用性が低下する。 データを複数の磁気ディスクに分割配置し,さらにサーバと磁気ディスクが1対1に対応しているので,複数サーバを用いた並列処理が可能となる。 |
ACID特性
| 用語 | 説明 |
|---|---|
| 原子性 Atomicity |
完全に実行されるか、まったく実行されないか |
| 一貫性 Consistency |
整合性を保つ |
| 独立性 Isolation |
トランザクションを同時に実行しても結果に影響なし |
| 耐久性 Durability |
障害が発生しても結果に影響なし |
3層スキーマ
| 用語 | 説明 |
|---|---|
| 外部スキーマ (サブスキーマ) |
ビュー。ユーザやプログラムからアクセスされる。 |
| 概念スキーマ | テーブル。現実世界のデータをモデリング。 外部スキーマと内部スキーマの間に位置。 |
| 内部スキーマ | 物理ファイル。データベースに対してただ一つ存在。 |
インデックス
| 用語 | 説明 |
|---|---|
| B木インデックス | データの分岐(枝分かれした「葉」)の先がすべて同一の階層に属しているような構造モデル。 ランダムアクセスを高速化。 最大格納レコード(kレコード。n段の場合) : \((2k+1)^n-1\) |
| B+木インデックス | B木に加えて順次処理も高速化。範囲検索も得意。 挿入・検索・削除が効率的に行える。 |
| ビットマップインデックス | キー値ごとにビットマップ (ビットの配列) を作成。取り得る値が少ない場合に有効。 論理演算 (カウント、AND、OR) は得意。 |
| ハッシュ | ハッシュ関数に基づく索引。完全一致検索にのみ利用。 |
NoSQL
NoSQLではロックは使用しない。| 用語 | 説明 |
|---|---|
| 結果整合性 | 分散した複製サイト間で更新内容を厳密に同期させずに,同期の一時的な遅れを許容する。 |
データウェアハウス
| 用語 | 説明 |
|---|---|
| データクレンジング | 業務系のデータベースから抽出したデータウェアハウスに格納するために,整合されたデータ属性やコード体系などに合うように変換及び修正を行う処理 |
| スライシング | データを分析するため、集計項目から2つ項目を選んで、二次元の表を作成。 |
| ダイジング | スライシングを使って縦横の項目をコロコロ変えて色んな角度でデータ分析。 |